Monitoring Analytics for In Situ Workflows at the Exascale
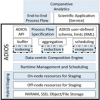
The Mona project is a collaboration between Georgia Tech, University of Oregon, Oak Ridge National Laboratory, and Princeton Plasma Physics Laboratory. Led by Dr. Greg Eisenhauer after Dr. Schwan's passing, the project is aimed at providing scalable platform and application monitoring for in situ workflows at the exascale.
The MONA(lytics) project seeks to understand, evaluate, and ultimately, control the online data flows generated by future exascale applications and the analytics processing applied to those flows: their volumes, speeds, and processing needs; the energy saved by online vs. offline data processing; the effects of next generation computer hardware and of the new ways of performing data management; and the tradeoffs in how well data is analyzed vs. the costs of doing so, when approximate methods are sufficient for the immediate scientific insights being sought.