RSVP: Runtime System for I/O staging in support of Voluminous in situ Processing of extreme scale data
Research Team:
ORNL: Scott Klasky (klasky@ornl.gov), Hasan Abbasi, Nagiza Samatova, Yuan Tian, Matthew Wolf; LBNL: Arie Shoshani, John K. Wu, Georgia Tech: Karsten Schwan, Greg Eisenhauer, Rutgers: Manish Parashar
Description: The advent of the exascale era is forcing a re-examination of the computational processes for science, and particularly those for scientific data management. In order to address increasing scales and associated complexity (e.g., new processing architectures, complex memory hierarchies, new programming paradigms and new requirements for energy efficiency and resilience), the interfaces used between computation, I/O, and storage must provide unprecedented levels of flexibility in how and where I/O actions are carried out to enable online data transformations and analytics. 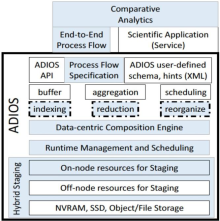 At these extreme scales, online data processing pipelines will need to be easily and dynamically composed, efficiently executed alongside the scientific simulations producing the data, and support reuse of computation and data. Furthermore, the need to seamlessly integrate experimental data is imposing additional demands on extreme-scale datamanagement solutions. The overarching goal of the RSVP project is to fundamentally address these challenges by developing model in which computational, data transformation and data analytic services can be easily and efficiently associated with and applied to science data as part of an end-to-end, in situ “process flow.”
At these extreme scales, online data processing pipelines will need to be easily and dynamically composed, efficiently executed alongside the scientific simulations producing the data, and support reuse of computation and data. Furthermore, the need to seamlessly integrate experimental data is imposing additional demands on extreme-scale datamanagement solutions. The overarching goal of the RSVP project is to fundamentally address these challenges by developing model in which computational, data transformation and data analytic services can be easily and efficiently associated with and applied to science data as part of an end-to-end, in situ “process flow.”
The resulting software solutions will be highly scalable, portable, and easy-to-use, and will enable the scientists can gain control of their science, allowing them to focus on scientific discovery in their own domain. Accelerating scientific productivity and the rate of insight in this way, demands new thinking and innovative solutions for managing the avalanche of data expected at extreme scales, which are central to the RSVP vision To achieve its goals, RSVP will leverage ADIOS, 2013 R&D 100 winner, which has helped over 30 communities in the past 5 years, to speed up I/O by over 10X compared to other popular technologies; as shown in Figure 2. Building on the early successes of the ADIOS framework, the design and realization of the our envisioned process flows will be done in coordination with strategically important applications, i.e., materials science, seismology, and fusion, each chosen to advance certain process flow technologies. The desired outcome of the RSVP project and this coordinated effort is a service-oriented-architecture (SOA), called the eXtreme Scale Service Architecture (XSSA), that permits scientists to retain control over the flow of data and data transformations/analysis, while allowing them to abstract away the extraneous complexity and implementation details of the data management. Furthermore, we aim to particularly facilitate novel extreme scale application process flows that incorporate runtime comparative analytics performed in-situ during the execution of the simulations.
RSVP Project Goals
Scientific Programming Abstractions: Defining semantically meaningful annotations and operations, both at the language level and at the process flow level, which can be used to guide the placement of data and computation tasks.
Data-centric Composition: Exploring data-centric mapping and scheduling to translate the abstract description of the concrete algorithmic components in the scientific process flow that reflects complex trade-offs in placement of data and computation.
Scalable Data Staging Substrate: Developing a data staging substrate that willsupport complex in-memory and off-node tasks that span across the deep-memory hierarchy levels, while also providing a tractable abstraction to support semantically specialized, distributed, shared resources that the higher levels software modules can easily utilize.
Data Transformations: Expanding the science toolbox with techniques for optimizing data layout and determining which parts of the data should be reorganized, compressed, or indexed. Such techniques will facilitate in situ code-to-code coupling, in situ analysis, and real-time correctness monitoring.
Autonomic Runtime Management: Exploring methods and models for controlling the data flows for extreme-scale science, in a cross-layer manner, with respect to performance, user utility, power consumption, and heterogeneous resources by decomposing the process flow both within and between selfmanaged domains, such as containers or ensembles in the exascale OS.